临沂网站维护高端快速建站
一、数据库操作
- 创建数据库
create database if not exists myhive;
- 查看数据库
use myhive;
desc database myhive;

- 创建数据库并指定hdfs存储
create database myhive2 location '/myhive2';
- 删除空数据库(如果有表会报错)
drop database myhive;
- 强制删除数据库,包含数据库下的表一起删除
drop database myhive cascade;
- 数据库和HDFS的关系
- Hive的库在HDFS上就是一个以.db结尾的目录
- 默认存储在:/user/hive/warehouse内
- 可以通过LOCATION关键字在创建的时候指定存储目录
- Hive中可以创建的表有好几种类型, 分别是:
- 内部表
- 外部表
- 分区表
- 分桶表
二、Hive SQL语法
1、表操作
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区 [CLUSTERED BY (col_name, col_name, ...) 分桶 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT DELIMITED | SERDE serde_name WITH SERDEPROPERTIES(property_name=property_value,..)] [STORED AS file_format] [LOCATION hdfs_path]
[] 中括号的语法表示可选。
| 表示使用的时候,左右语法二选一。
建表语句中的语法顺序要和语法树中顺序保持一致。
字段简单说明
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项 来忽略这个异常。
- EXTERNAL 外部表
- COMMENT: 为表和列添加注释。
- PARTITIONED BY 创建分区表
- CLUSTERED BY 创建分桶表
- SORTED BY 排序不常用
- ROW FORMAT DELIMITED 使用默认序列化LazySimpleSerDe 进行指定分隔符
- SERDE 使用其他序列化类 读取文件
- STORED AS 指定文件存储类型
- LOCATION 指定表在HDFS上的存储位置。
- LIKE 允许用户复制现有的表结构,但是不复制数据
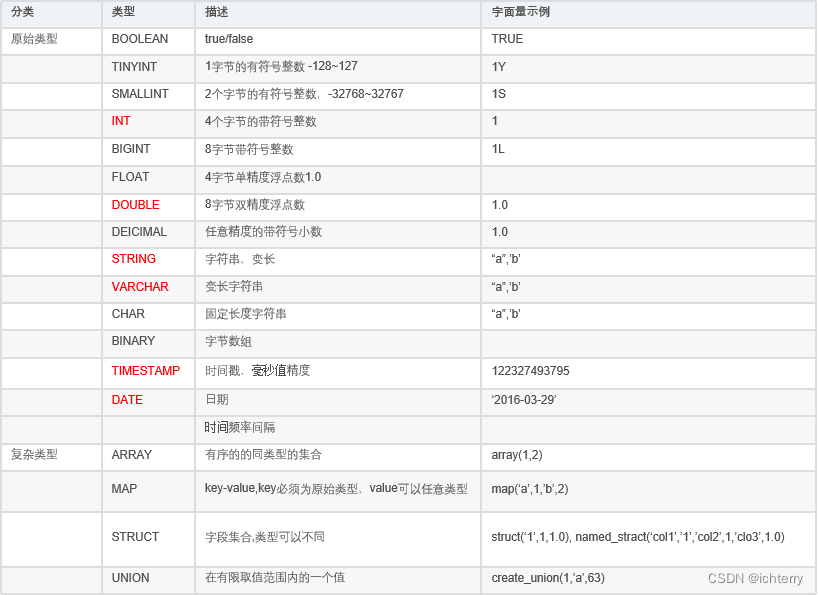
- 数据类型
- 创建表
CREATE TABLE test(id INT, name STRING, gender STRING);
- 删除表
DROP TABLE test;
2、内部表操作
- 默认创建的就是内部表,如下举例:
create database if not exists myhive;
use myhive;
create table if not exists stu2(id int,name string);
insert into stu2 values (1,"zhangsan"), (2, "lisi");
select * from stu2;
- 在HDFS上,查看表的数据存储文件

3、外部表操作
# 创建外部表
create external table test_ext(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext';
# 可以看到,目录/tmp/test_ext被创建
select * from test_ext #空结果,无数据
# 上传数据:
hadoop fs -put test_external.txt /tmp/test_ext/
#现在可以看数据结果
select * from test_ext
# 删除外部表(但是在HDFS中,数据文件依旧保留)
drop table test_ext;
- 内外部表转换(EXTERNAL=TRUE 外或FALSE 内,注意字母大写)
alter table stu set tblproperties('EXTERNAL'='TRUE');
4、数据加载和导出
- 先建表
CREATE TABLE myhive.test_load(dt string comment '时间(时分秒)', user_id string comment '用户ID', word string comment '搜索词',url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
- 数据加载方式一:基于HDFS进行load加载数据(不保留原始文件)
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
search_log.txt文件内容如下:

- 数据加载方式二:将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表(保留原始文件)
INSERT INTO TABLE tbl1 SELECT * FROM tbl2;
INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;
- 将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
- 将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
- 将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
- hive表数据导出
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txtbin/hive -f export.sql > /home/hadoop/export4/export4.txt
5、分区表
- 在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了
同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。
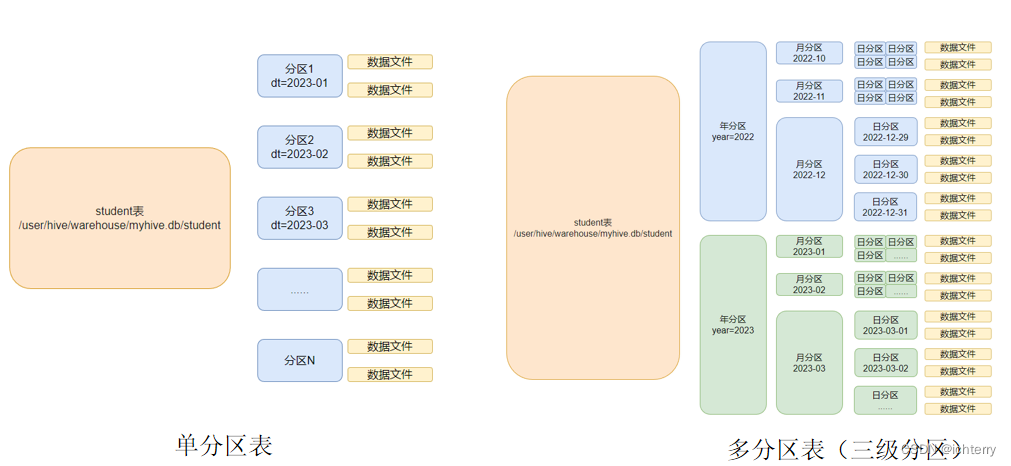
- 基本语法
create table tablename(...) partitioned by (分区列 列类型, ......) row format delimited fields terminated by ''; - 创建分区表
create table score(s_id string, c_id string, s_score int) partition by (month string) row format delimited fields terminated by '\t';
- 创建多个分区表
create table score(s_id string, c_id string, s_score int) partition by (year string,month string,day string) row format delimited fields terminated by '\t';
- 加载数据到分区表中
load data local inpath '/export/server/hivedata/score.txt' into table score partition(month='202403');
- 加载数据到多分区表中
load data local inpath '/export/server/hivedata/score.txt' into table score partition(year='2024',month='03',day='27');
- 查看分区表
show partitions score;
- 添加一个分区
alter table score add partition(month='202403');
- 同时添加多个分区
alter table score add partition(month='202403') partition(month='202402');
- 删除分区
alter table score drop partition(month='202403');
6、分桶表
- 开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;
- 创建分桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
- 桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select.
所以,比较好的方式是:
- 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
- 然后通过insert select 从临时表向桶表插入数据
# 创建普通i表
create table course_common(c_id string, c_name string, t_id string) row format delimited fields terminated by '\t';
# 普通表中加载数据
load data local inpath '/export/server/hivedata/course.txt' into table course_common;
# 通过insert overwrite给桶表加载数据
insert overwrite table course select * from course_common cluster by(c_id);
- 为什么不可以用load data,必须用insert select插入数据:
- 问题就在于:如何将数据分成三份,划分的规则是什么?
- 数据的三份划分基于分桶列的值进行hash取模来决定
- 由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已
所以无法用于分桶表数据插入。
- Hash取模
- Hash算法是一种数据加密算法,其原理我们不去详细讨论,我们只需要知道其主要特征:
- 同样的值被Hash加密后的结果是一致的
比如字符串“hadoop”被Hash后的结果是12345(仅作为示意),那么无论计算多少次,字符串“hadoop”的结果都会是12345。
比如字符串“bigdata”被Hash后的结果是56789(仅作为示意),那么无论计算多少次,字符串“bigdata”的结果都会是56789。
- 基于如上特征,在辅以有3个分桶文件的基础上,将Hash的结果基于3取模(除以3 取余数)
那么,可以得到如下结果:
- 无论什么数据,得到的取模结果均是:0、1、2 其中一个
- 同样的数据得到的结果一致,如hadoop hash取模结果是1,无论计算多少次,字符串hadoop的取模结果都是1
跳转到《Apache Hive的基本使用语法(二)》
至此,分享结束!!!