哪个网站能看到医生做的全部手术好f123网站
一、VMware准备机器
首先准备三台机器
这里我直接使用 VMware 构建三个虚拟机 都是基于 CentOS7
然后创建新用户
部署 es 需要单独创建一个用户,我这里在构建虚拟机的时候直接创建好了
然后将安装包上传
可以使用 rz 命令上传,也可以使用工具上传
工具包地址:链接:https://pan.baidu.com/s/1sGJW4jErofM3aj2CeU1ncg?pwd=eo6a
提取码:eo6a
上传后进行解压
三台机器都需要
tar zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz 解压完成

二、配置 jdk
es7 以上内置了 jdk 环境,

但是需要配置一下:
# linux 进入用户主目录,比如/home/heyue/es/目录下,设置用户级别的环境变量
vim .bash_profile
#设置ES_JAVA_HOME和ES_HOME的路径
export ES_JAVA_HOME=/home/heyue/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/heyue/es/elasticsearch-7.17.3
export PATH=$PATH:/home/heyue/es/elasticsearch-7.17.3/jdk/bin
#执行以下命令使配置生效
source .bash_profile三、先单机启动
这里可以先启动三台单机的 es
然后配置 ElasticSearch
配置 elasticsearch.yaml 文件
vim elasticsearch.yml#开启远程访问
network.host: 0.0.0.0
#单节点模式 初学者建议设置为此模式
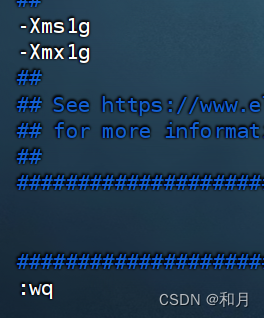
discovery.type: single-node修改 JVM 内存 我这里内存比较小,可以根据自己服务器情况进行设置
修改config/jvm.options配置文件,调整jvm堆内存大小
启动 es
bin/elasticsearch # -d 后台启动
bin/elasticsearch -d启动成功后通过浏览器访问
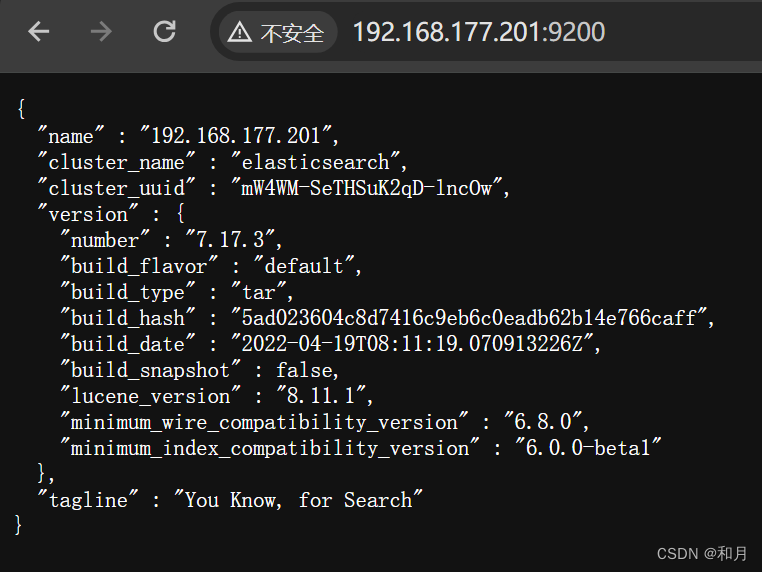
如果访问不通,可以看下防火墙端口是否开放:
添加防火墙规则:
打开端口,例如打开端口 9200(HTTP):
sudo firewall-cmd --zone=public --add-port=9200/tcp --permanent重新加载防火墙规则以应用更改:
sudo firewall-cmd --reload查看已打开的端口:
sudo firewall-cmd --list-ports然后可以看到 我这里三台 单机 es 已经启动成功

四、安装 kibana
然后随便找一台机器安装 kibana
同样的上传压缩包,解压
修改配置文件
vim config/kibana.yml修改一下几个地方
端口:
![]()
网卡监听:
![]()
es URL:
![]()
中文:
![]()
然后启动 kibana
nohup bin/kibana &
可以看到启动成功
这里注意,别忘了 开放端口 5601

五、集群配置
域名映射
可以先进行域名映射,便于后面维护
执行命令:
vim /etc/hosts注意:这里如果其实文件只读,可以对文件增加写入权限,也可以使用 root 进行修改
添加以下配置:
192.168.177.201 es-node1
192.168.177.201 es-node2
192.168.177.201 es-node3
三台机器同样的操作
然后修改 elasticsearch.yml 配置
首先把刚刚单机配置注释
![]()
其他配置:
# 指定集群名称3个节点必须一致
cluster.name: es-cluster
#指定节点名称,每个节点名字唯一
node.name: node-1
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#指定web端口
#http.port: 9200
#指定tcp端口
#transport.tcp.port: 9300
#用于节点发现
discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"配置好之后,先 kill 掉刚刚启动的进程,三台机器同样的操作

!!!注意修改完成之后,一定一定要记得切换用户,不要使用 root!不要使用 root!不要使用 root!不要使用 root!不要使用 root!不要使用 root!
然后由于刚刚进行单机启动了,所以还需要删除 data 文件夹
# 注意:如果运行过单节点模式,需要删除data目录, 否则会导致无法加入集群
rm -rf data
# 启动ES服务 bin/elasticsearch -d
重新启动:
bin/elasticsearch -d报错以及解决方案
发现报错可以按照以下方案解决:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错

然后进行配置:
注意需要先切换到 root
#切换到root用户
vim /etc/security/limits.conf末尾添加如下配置:* soft nofile 65536* hard nofile 65536* soft nproc 4096* hard nproc 4096[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf改为如下配置:
* soft nproc 4096[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]#或者指定配置单节点(集群单节点)
discovery.type: single-node[5]

注意:es默认不能用root用户启动,生产环境建议为elasticsearch创建用户。
#为elaticsearch创建用户并赋予相应权限
adduser es
passwd es
chown -R es:es elasticsearch-7.17.3配置完成后,注意,一定一定 要记得切换用户,es 不支持 root 启动
如果已经使用 root 启动报错了,需要先执行以下命令进行替换
回到 es 文件夹,执行以下命令,里面的 heyue 换成自己的用户名
chown -R heyue:heyue elasticsearch-7.17.3如果出现以下信息,那么恭喜,集群搭建成功

六、更新 kibana 配置
然后还需要修改一下 kibana 配置,配置为集群
vim config/kibana.ymlelasticsearch.hosts: ["http://192.168.65.174:9200","http://192.168.65.192:9200","http://192.168.65.204:9200"]
七、安装 Cerebro 客户端
先上传,然后解压
unzip cerebro-0.9.4.zip
解压完成后直接启动
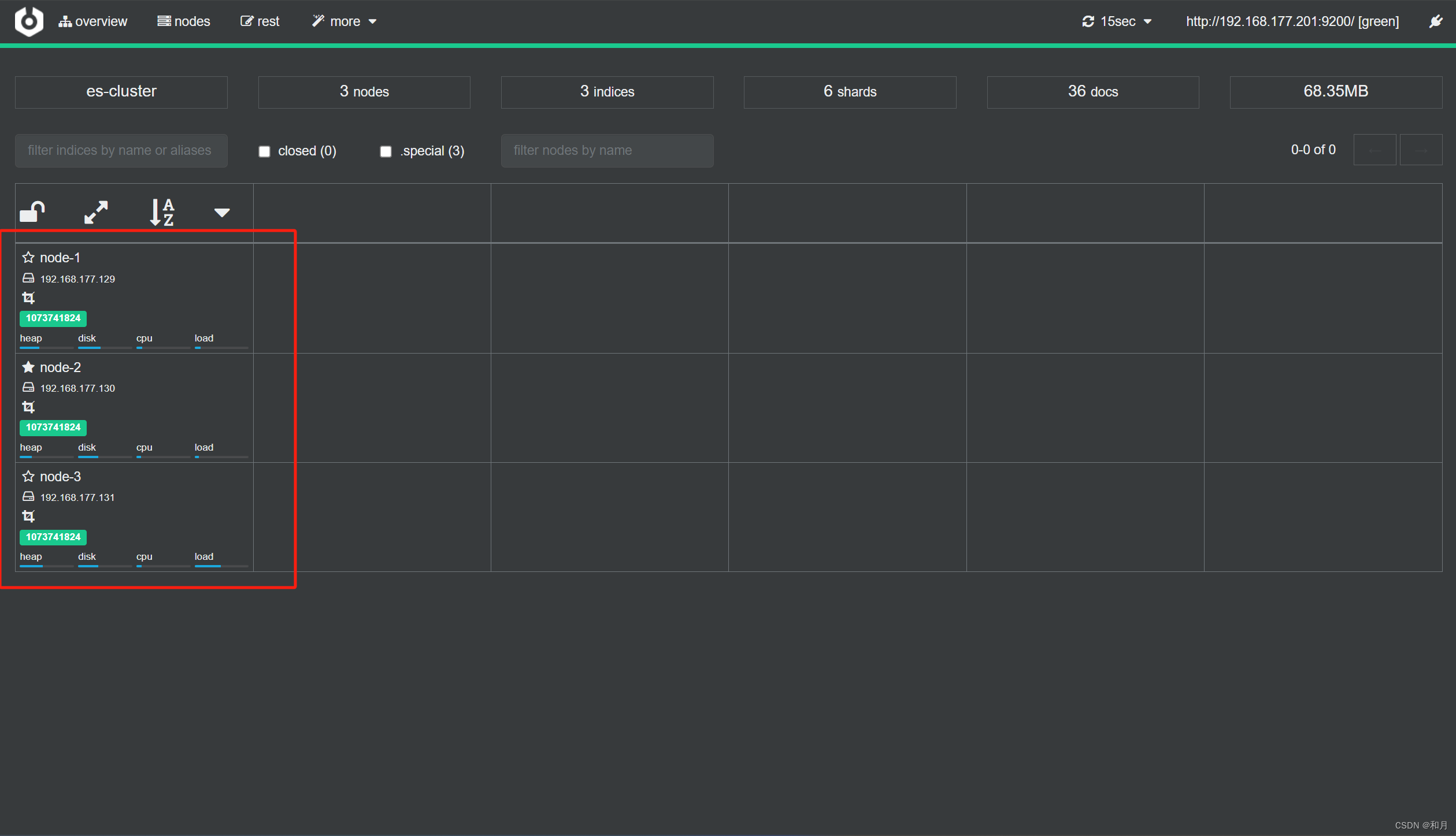
nohup bin/cerebro > cerebro.log &然后页面上输入 es 地址链接

到这里,看到这个页面,恭喜 es 集群已经完成搭建完成
 这里是基于原生安装包的方式进行搭建,基于 docker 搭建也是一样的,使用docker 启动三个单机,然后修改里面的配置文件即可
这里是基于原生安装包的方式进行搭建,基于 docker 搭建也是一样的,使用docker 启动三个单机,然后修改里面的配置文件即可
未来的自己一定会感谢今天努力的自己,加油,我们一起进步!!!