衢州做外贸网站的公司巩义网络推广公司
对近期一些MLLM(Multimodal Large Language Model)的总结 - 知乎本文将从模型结构,训练方法,训练数据,模型表现四个方面对近期的一些MLLM(Multi-modal Large Language Models)进行总结并探讨这四个方面对模型表现的影响。本文覆盖的MLLM包括:LLaVA, MiniGPT-4, mPLUG-Owl, …![]() https://zhuanlan.zhihu.com/p/655770704
https://zhuanlan.zhihu.com/p/655770704
连接不同模态的可学习接口:挑战在于如何将视觉内容有效的转换为LLM能理解的文本。1.利用一组可学习的query token以查询方式提取信息,Flamingo和BLIP2,2.基于投影,llava采用简单的线性层嵌入图像特征,MedVInT-TE则使用两层多层感知机,3.LLaMA-Adapter在transformer中引入一个轻量级适配器模块进行训练,LaVIN设计了一个多模态适配器混合模型,动态决定多模态嵌入的权重。
1.related work
multimodel instruction-following agents. 1.端到端训练模型,2.langchain,例如visual chatgpt.
instruction tuning. Flamingo,Blip2,KOSMOS-1。
2.GPT-assisted Visual instruction data generation
总共收集了15.8w的语言-图像instruct样本,其中包括5.8w个对话样本,2.3w个详细描述样本和7.7w个复杂推理样本。
3.Visual instruction tuning
3.1 architecture
主要目标是有效利用预训练的llm和视觉模型的能力,llama作为llm,预训练的clip视觉编码器ViT-L/14,提供Zv,用一个简单的线性层来将图像特征连接到单词embedding空间,用一个可训练的投影矩阵w将Zv转换为语言embedding标记Hq,其维度与语言模型中的单词embedding空间相同。 也有复杂的方式,例如Flamingo中的gated cross-attention和BLIP2中的Q-former。
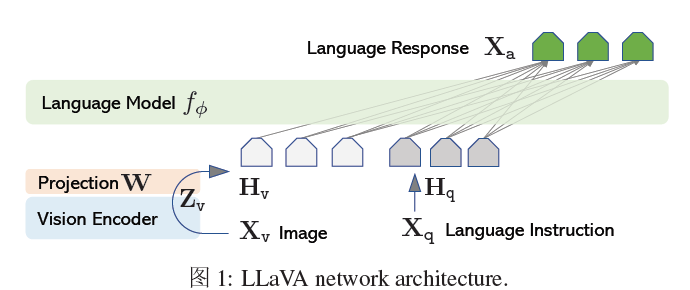
LLaVA主要由三部分组成:Pretrained LLM,Pretrained Vision Encoder和Projection Layers。其中,Pretrianed LLM即为目前比较火的Decoder-only language model,比如LLaMA,LLaMA-2等。Pretrained Vision Encoder即为一个预训练的视觉编码器,通常是CLIP的中的视觉分支。而连接在vison encoder和LLM之间的Projection Layers即为一个简单的线形层,这个projector的作用是将image通过vision encoder得到的visual feature从visual space转化到language space从而可以输入LLM。
整个模型的forward过程是先将图片输入vision encoder得到图片的visual feature,然后visual feature经过projection layers得到对应的linguistic vector 。然后,将prompt(通常为VQA认为中的问题,或者目前比较火的Instruction)通过LLM的word embedding层,得到prompt对应的linguistic feature。然后将图像的vector和文字vector concatnate起来得到一个长序列。将长序列输入LLM,然后LLM自回归地去生成prompt对应的结果,这个结果可以是VQA中的答案,也可以是图片的caption。
3.2 training
llava训练包含两个阶段:预训练和微调。
LLaVA的预训练阶段是在Image-Text pair数据上进行的,在这个过程之中,只有Projection layers部分是可训练的,模型的其他部分(LLM和vision encoder)都是冻住的。预训练这个阶段是为了训练一个较好的projection layer可以将visual feature映射到linguistic space。换句话说,为了让vision encoder的output space和LLM的input space实现一个对齐。这个阶段结束之后模型获得了一个初步的理解图像的能力。
LLaVA的微调阶段分为两种,一种是在instruct template数据上进行Instruct Tuning,另一种是在ScienceQA数据集上进行微调。这里我们以Instruct Tuning为主要展开。首先,这个阶段中可训练的部分包括整个LLM和projection layer。这一阶段可以对应于目前比较火的LLM的Instruction fine tuning,目的是为了让模型更好地遵循用户给出的Instruction。换句话说,为了让模型更好地和人类意图进行对齐。所以,这个阶段的作用可以类比到GPT-3向InstructGPT的转变,即模型可以更好地遵循人类指令。
4.训练数据
对应于LLaVA的两个训练阶段,LLaVA的训练数据也分为两部分:预训练阶段的数据和微调阶段的数据。
预训练阶段的数据直接来自CC3M。CC3M包含3 million的图像文本对,作者通过text中的noun-phrase的频率对3 million的数据进行了过滤最终得到595K个图像文本对。然后,作者通过GPT-4生成一些多样化的Instruction,用这些Instruction将简单的图像文本对扩展成了[Image, Instruction; Caption]的形式。

指令微调阶段的数据也是由GPT-4辅助生成的。由于GPT-4是纯文本输入,所以要使用GPT-4来生成一些针对图片的问题和答案就需要将图片表示成GPT-4可以理解的形式。在这里,对于一张图片,作者用5句caption以及图片中object的bounding box的坐标数值来表示一张图片。然后,通过设计特定的prompt以及例子,让GPT-4生成针对一张图片的conversation, detailed description和complex reasoning。

5.Experiments
作者从COCO Caption的val split中抽取了30张图片,针对每张图片设计了short question,detailed question和complex reasoning question,共得到90个evaluation sample。针对这90个sample,作者使用预训练+指令微调之后的LLaVA和GPT-4分别生成了答案,然后借助GPT-4对LLaVA生成的答案进行了Evaluation,并让GPT-4进行打分,结果如下:
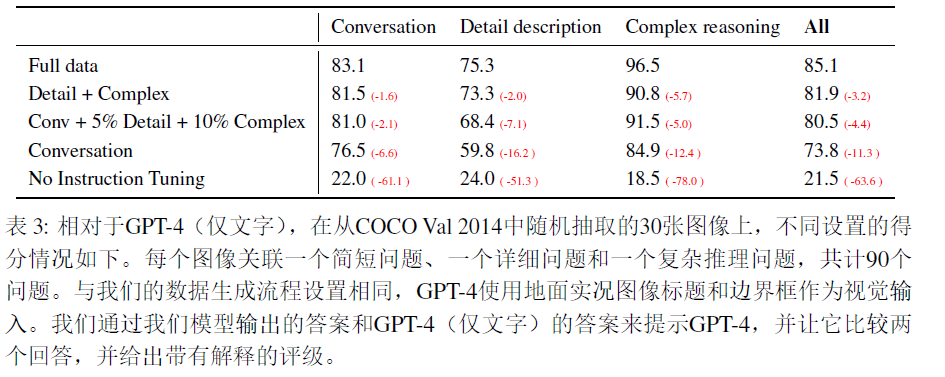
llava当时的GPT4还不支持图像输入,因此这样的测评也不完全能够展示GPT4的能力。