wordpress 兼容移动端seo优化大公司排名
引子
你可能听说过 Transformer,听说它是 ChatGPT 的核心结构,或者它是深度学习的一个神级发明,甚至是“自然语言处理的变革性里程碑”,各大教育机构和电子书也有深刻的见解,但当你去百度、知乎、B站一搜,全是一些看不懂的专业术语,比如“多头注意力”、“位置编码”、“层归一化”、“残差连接”……
那Transformer 到底是个啥?它到底在干嘛?今天我们来彻底讲清楚 Transformer,到底是什么,怎么来的,怎么用,为什么它这么强。
一句话理解 Transformer:
Transformer 是一种专门用来处理“序列数据”(比如一段文字、一个句子、一串代码)的深度学习网络结构,它的核心思想是:用注意力机制代替传统的循环神经网络(RNN),让模型可以并行计算,从而实现更快、更准、更强。
框架
传统模型都有什么问题?拿RNN和CNN等传统模型框架和Transformer做下比对。
1. 循环神经网络(RNN)
- RNN是循环神经网络,能处理语音、文字等序列数据,通过循环结构捕捉时序依赖。
比如输入一句话,比如 “I love you”,RNN 是一个一个词读进去的:- 第一步输入 “I”,得到一个状态
- 第二步输入 “love”,结合前面的状态,再输出新的状态
- 第三步输入 “you”,再更新状态
- 存在问题:
- 一个词一个词处理,串行处理太慢。
- 长句子信息容易忘掉前面说了啥,比如翻译长句子会忘记主语是谁。
2. 卷积神经网络(CNN)
- CNN是专门处理图像的深度学习模型,能自动识别图像中的物体,也能处理文本。
问题: - 不太擅长处理句子里远距离的依赖关系,比如“我昨天吃了一个苹果,它很甜”,“它”指的是“苹果”,这个跳跃 CNN 很难搞清楚。
3.Transformer
2017 年,谷歌一篇论文横空出世:
Attention Is All You Need(《注意力机制就是一切》)
论文里首次提出了 Transformer 模型,之后各种 GPT、BERT、ChatGPT、Claude、文心一言等大模型,全是 Transformer 系列的!
整体结构介绍
你可以把 Transformer 想成一个复杂的“翻译机器人”,由两大模块组成:
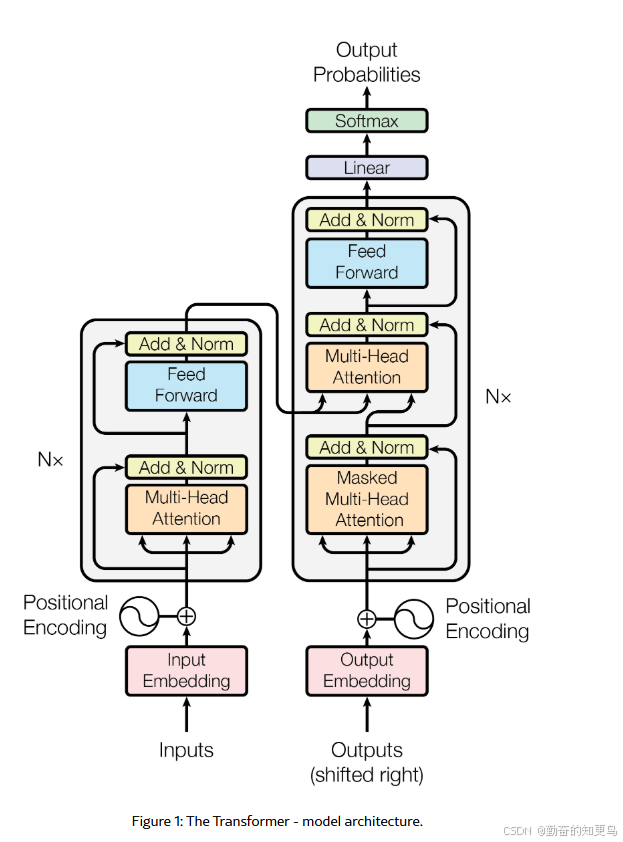
- Encoder 编码器:读懂输入的句子,把每个词变成一个向量,提取出句子中各词之间的关系。
- Decoder 解码器:根据 Encoder 的输出,逐个生成目标语言的单词。
核心概念详解
1. 注意力机制(Attention)
这是 Transformer 的灵魂,重点来了!
什么是注意力?
举个例子:
当你读到这句话:“我昨天吃了一个苹果,它很甜。”
你大脑会自然知道“它”指的是“苹果”,你在理解“它”的时候,其实“注意力”放在了“苹果”这个词上。
Transformer 的注意力机制就是模仿人脑这种机制:
对于当前的词,它会自动“关注”句子中和它最相关的词。
最经典的 Attention 公式:Attention(Q, K, V) = softmax(QK^T / √d) * V
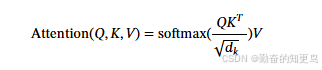
- Q(Query):查询向量(比如“它”)
- K(Key):键向量(比如“苹果”)
- V(Value):值向量(词的表示)
意思是:用 Q 去和 K 比较相似度(点积),算出每个词和“它”的相关程度,然后根据这些相关程度加权平均 V。
最后就得到了一个融合了相关信息的向量表示!
2. 多头注意力机制(Multi-head Attention)
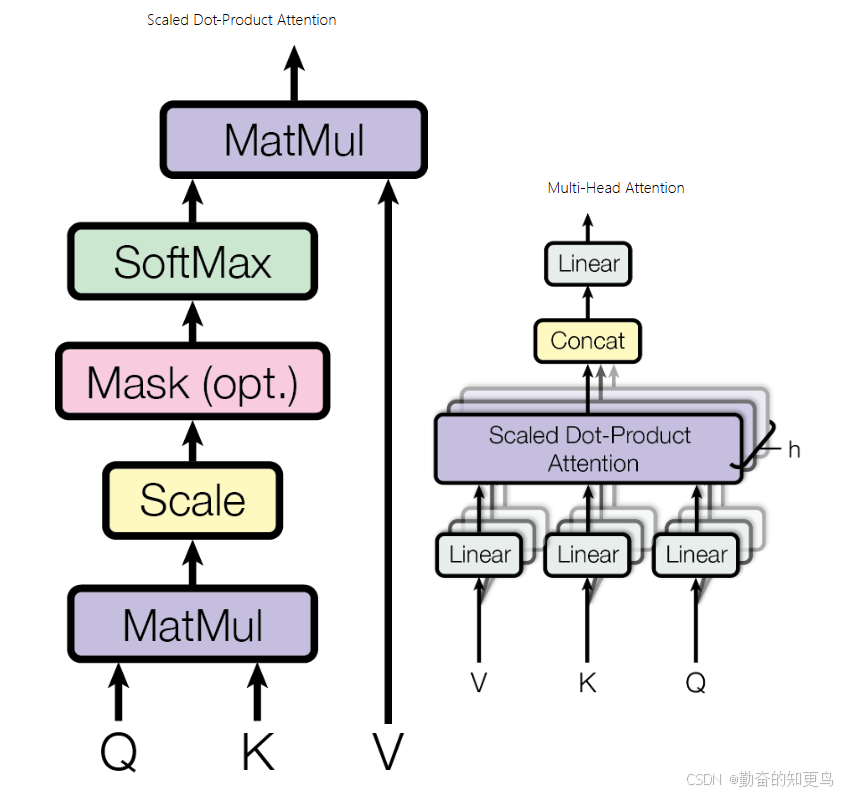
一个头看的角度有限,就像一只眼睛看世界没那么立体。
Transformer 同时用多个“注意力头”来看句子,每个头看不同的关系:
- 有的头专门关注形容词和名词的关系
- 有的头关注动词和主语之间的关系
- 有的看长距离依赖……
然后把这些信息综合起来,模型就更聪明啦!
3. 位置编码(Positional Encoding)
注意!Transformer 结构没有像 RNN 那样的顺序处理。
所以它根本不知道哪个词是第一个、哪个是第二个……
为了解决这个问题,它在每个词的向量里加上一个位置编码,让模型知道哪个词在前,哪个词在后。
可以简单理解为:
把“词义向量 + 位置信息”组合在一起,才能真正懂句子。
4. 残差连接 & 层归一化
这两个概念就是为了让深层神经网络不容易“死掉”或者“学崩”。
简单说:
- 残差连接(ResNet):跳过一部分计算,避免信息丢失。
- LayerNorm(层归一化):让每一层的输出数值保持稳定,不会炸或消失。
5. 前馈神经网络(FFN)
Transformer 中每个编码器层不仅有注意力模块,还有一个小小的前馈神经网络:
- 就是两层全连接层 + ReLU 激活函数
- 每个词的表示单独喂进去,进一步处理和提取特征
Encoder 和 Decoder 的结构图简化一下:
Encoder(每层):
输入嵌入 + 位置编码↓
多头自注意力机制(自己和自己注意)↓
残差连接 + LayerNorm↓
前馈神经网络(FFN)↓
残差连接 + LayerNorm
Decoder(每层):
目标词嵌入 + 位置编码↓
Masked 多头自注意力(只看前面的词)↓
残差连接 + LayerNorm↓
跨注意力(和Encoder输出做注意力)↓
残差连接 + LayerNorm↓
前馈神经网络(FFN)↓
残差连接 + LayerNorm
6. 总结
| 优点 | 说明 |
|---|---|
| 并行处理 | 不像RNN那样一步步,速度更快 |
| 全局依赖建模 | 注意力机制可以看全局信息 |
| 模块化设计 | 每一块都很独立,扩展容易 |
| 表达能力强 | 多头注意力可以挖掘复杂关系 |
| 通用性强 | 既能做文本,又能做图像、音频、代码! |
Transformer 是一种结构化的神经网络,用“注意力机制”代替了传统的循环神经网络,通过自注意力、多头机制、前馈网络、位置编码等模块,实现了对文本序列的高效建模,被广泛应用于翻译、写作、聊天机器人、语音识别、代码生成等各种 AI 场景中。
- 它像一个聪明的阅读器,能自动识别出一个句子中哪些词彼此相关。
- 它不像传统方法那样死板地一个字一个字看,而是像高考作文审题老师,一眼看出重点在哪儿。
- 它不仅能“翻译”句子,还能“续写”小说、“理解”语义、“回答”问题……AI时代的核心引擎!
资料
- 框架推荐:
PyTorch或TensorFlow - 学习资源:
- Transformer 官方论文:Attention Is All You Need
- 代码实战推荐:哈佛 NLP 教程 (The Annotated Transformer)
GitHub 地址:https://github.com/harvardnlp/annotated-transformer
尾声
如果你是初学者(反正我是),看了这篇博客能对 Transformer 有一个整体认识,那就是我写这篇文章最大的动力。
引用某著名讲师的名言:
既然我们不能阻挡AI的脚步,那我们就躬身入局,深入理解AI底层,这样我们才能掌控AI,让我们自己变得更加强大!
AI 时代不怕出身普通,只怕不敢上手!咱们普通人也能看懂、学会、用好 Transformer!