wordpress加上live2d宁波seo专员
这是我的第312篇原创文章。
一、引言
单站点多变量输入多变量输出单步预测问题----基于LSTM实现。
多输入就是输入多个特征变量
多输出就是同时预测出多个标签的结果
单步就是利用过去N天预测未来1天的结果
二、实现过程
2.1 读取数据集
df=pd.read_csv("data.csv", parse_dates=["Date"], index_col=[0])
print(df.shape)
print(df.head())
fea_num = len(df.columns)df:

2.2 划分数据集
# 拆分数据集为训练集和测试集
test_split=round(len(df)*0.20)
df_for_training=df[:-test_split]
df_for_testing=df[-test_split:]# 绘制训练集和测试集的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
plt.show()共5203条数据,8:2划分:训练集4162,测试集1041。
训练集和测试集:

2.3 归一化
# 将数据归一化到 0~1 范围(整体一起做归一化)
scaler = MinMaxScaler(feature_range=(0,1))
df_for_training_scaled = scaler.fit_transform(df_for_training)
df_for_testing_scaled=scaler.transform(df_for_testing)2.4 构造LSTM数据集(时序-->监督学习)
def createXY(data, win_size, target_feature_idxs):passwin_size = 12 # 时间窗口
target_feature_idxs = [0, 1, 2, 3, 4] # 指定待预测特征列索引
trainX, trainY = createXY(df_for_training_scaled, win_size, target_feature_idxs)
testX, testY = createXY(df_for_testing_scaled, win_size, target_feature_idxs)
print("训练集形状:", trainX.shape, trainY.shape)
print("测试集形状:", testX.shape, testY.shape)# 将数据集转换为 LSTM 模型所需的形状(样本数,时间步长,特征数)
trainX = np.reshape(trainX, (trainX.shape[0], win_size, fea_num))
testX = np.reshape(testX, (testX.shape[0], win_size, fea_num))print("trainX Shape-- ",trainX.shape)
print("trainY Shape-- ",trainY.shape)
print("testX Shape-- ",testX.shape)
print("testY Shape-- ",testY.shape)滑动窗口设置为12:
取出df_for_training_scaled第【1-12】行第【1-5】列的12条数据作为trainX[0],取出df_for_training_scaled第【13】行第【1-5】列的1条数据作为trainY[0];依此类推。最终构造出的训练集数量(4150)比划分时候的训练集数量(4162)少一个滑动窗口(12)。
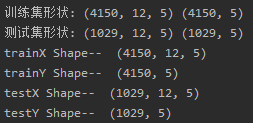
trainX是一个(4150,12,5)的三维数组,三个维度分布表示(样本数量,步长,特征数),每一个样本比如trainX[0]是一个(12,5)二维数组表示(步长,特征数),这也是LSTM模型每一步的输入。

trainY是一个(4150,5)的二维数组,二个维度分布表示(样本数量,标签数),每一个样本比如trainY[0]是一个(5,)一维数组表示(标签数,),这也是LSTM模型每一步的输出。

2.5 建立模拟合模型
# 输入维度
input_shape = Input(shape=(trainX.shape[1], trainX.shape[2]))
# LSTM层
lstm_layer = LSTM(128, activation='relu')(input_shape)
# 全连接层
dense_1 = Dense(64, activation='relu')(lstm_layer)
dense_2 = Dense(32, activation='relu')(dense_1)
# 输出层
output_1 = Dense(1, name='Open')(dense_2)
output_2 = Dense(1, name='High')(dense_2)
output_3 = Dense(1, name='Low')(dense_2)
output_4 = Dense(1, name='Close')(dense_2)
output_5 = Dense(1, name='AdjClose')(dense_2)
model = Model(inputs = input_shape, outputs = [output_1, output_2, output_3, output_4, output_5])
model.compile(loss='mse', optimizer='adam')
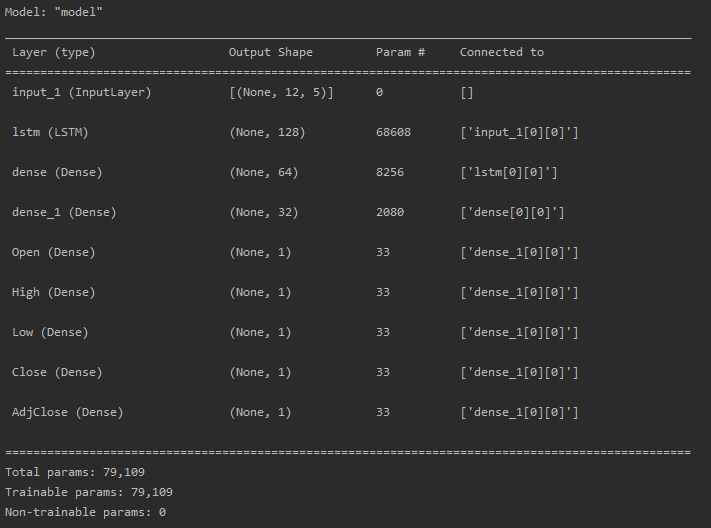
model.summary()这是一个多输入多输出的 LSTM 模型,接受包含12个时间步长和5个特征的输入序列,在经过一层128个神经元的 LSTM 层和5个全连接层后,输出5个单独的预测结果,分别是 Open、High、 Low、Close和 AdjClose。
进行训练,这里[trainY[:,i] for i in range(trainY.shape[1])]把原来的trainY做了转置,是一个(5,4150)的二维数组,分别表示(标签数,样本数)。相当于建立了5个通道,每个通道是(4150,)的一维数组。
history = model.fit(trainX, [trainY[:,i] for i in range(trainY.shape[1])], epochs=20, batch_size=32)2.6 进行预测
进行预测,上面我们分析过模型每一步的输入是一个(12,5)二维数组表示(步长,特征数),模型每一步的输出是是一个(5,)一维数组表示(标签数,)
prediction_test = model.predict(testX)如果直接model.predict(testX),testX的形状是(1029,12,5),是一个批量预测,输出prediction_test是一个(5,1029,1)的三维数组,prediction_test[0]就是第一个标签的预测结果,prediction_test[1]就是第二个标签的预测结果...多输出就是同时预测出多个标签的结果。

2.7 预测效果展示
分析一下第一个变量open的效果,i=0:
prediction_train = model.predict(trainX)
prediction_train0=model.predict(trainX)[i]
prediction_train_copies_array = ...
pred_train=...
original_train_copies_array = trainY
original_train=...
print("train Pred Values-- ", pred_train)
print("\ntrain Original Values-- ", original_train)
plt.plot(df_for_training.index[win_size:,], original_train, color = 'red', label = '真实值')
plt.plot(df_for_training.index[win_size:,], pred_train, color = 'blue', label = '预测值')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.xticks(rotation=45)
plt.ylabel('Stock Price')
plt.legend()
plt.show()训练集真实值与预测值:

prediction_test = model.predict(testX)
prediction_test0=model.predict(testX)[i]
prediction_test_copies_array = ...
pred_test=...
original_test_copies_array = testY
original_test=...
print("\ntest Original Values-- ", original_test)
plt.plot(df_for_testing.index[win_size:,], original_test, color = 'red', label = '真实值')
plt.plot(df_for_testing.index[win_size:,], pred_test, color = 'blue', label = '预测值')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.xticks(rotation=45)
plt.ylabel('Stock Price')
plt.legend()
plt.show()测试集真实值与预测值:

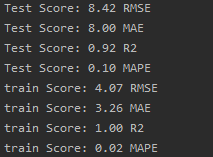
2.8 评估指标
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。