新网互联 网站上传域名污染查询网站
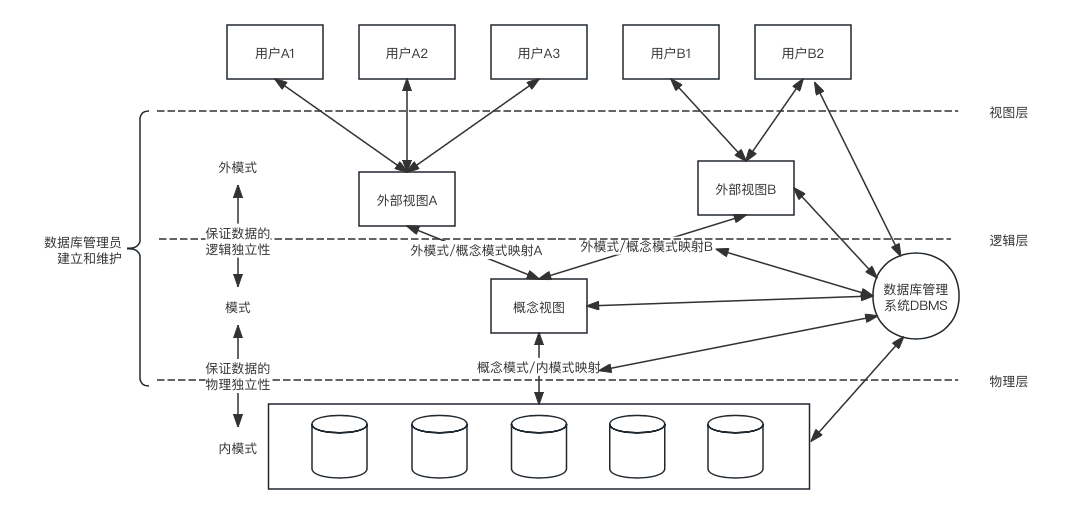
一、数据库三级模式
三个抽象层次:
1. 视图层:最高层次的抽象,描述整个数据库的某个部分的数据
2. 逻辑层:描述数据库中存储的数据以及这些数据存在的关联
3. 物理层:最低层次的抽象,描述数据在存储器中时如何存储的
数据库的三级模式:
1. 外模式(用户模式、子模式):用户与数据库系统的接口,是用户需要使用的部分数
据的描述
2. 概念模式(模式):数据库中全部数据的逻辑结构和特征的描述,反应数据库的结构
及其联系,是相对稳定的
3. 内模式(存储模式):是数据物理结构和存储方式的描述,是数据在数据库内部的表
示方式。定义所有的内部记录类型、索引和文件的组织方式以及数据控制方面的细节。
二、关系型数据库
关系模型是关系型数据的基础
关系模型组层:关系数据结构、关系操作集合、关系完整性规则
关系的完整性约束:
完整性规则保证当授权用户对数据做修改时不会破坏数据的一致性,防止数据的意外破
坏。分为:
实体完整性:要求每个表必须有主键,且组建必须唯一且非空
参照完整性:实体之间的连续描述
用户定义完整性:由应用环境决定的因素(如年纪必须大于0)
关系运算:
并(Union),差(difference),交(Intersection)与数学中的概念类似
笛卡尔积:R为n目的元数,S的m目的元数,R×S为(n+m)目的元组集合
投影(Projection):垂直方向上(列)的运算
选择(Selection):水平方向上(行)的运算
连接(Join):
θ连接:笛卡尔积中选取属性满足一定条件的元组
等值链接:θ为“=”时
自然连接:两个关系中进行比较的分量必须是相同的属性组,别再结果中去掉重复
的
除:同时进行水平和垂直方向上的运算。给丁关系R(X,Y)和S(Y,Z)。则R➗S应当
满足元组在X的分量值x包含在S在属性组Y上投影的集合。
外连接:
左外连接:用左侧原则去匹配右侧原则,空值用null填充
右外连接:用右侧原则去匹配左侧原则,空值用null填充
全外连接:先进行左外连接,再进行右外连接
规范化(数据库范式)
第一范式(1NF):
若关系模式R的每个分量都是不可再分的数据项,则R属于第一范式
1NF存在的问题:1. 数据冗余度大;2. 插入一场;3.修改一场;4. 删除异常
第二范式(2NF):
若关系模式R属于1NF,且每个非主属性完全依赖于码,则关系模式属于第二范
式,即1NF消除了非主属性对码的部分函数依赖。(每个非主属性必须用所有的码才能
推导出,而不是部分码就可以推导出)
第三范式(3NF):
当2NF的前提下,消除了非主属性对码的传递函数依赖(非主属性不能通过其他非
主属性推导得出)
BCNF(巴克斯范式):
当3NF消除了主属性对码的部分函数依赖和传递函数依赖,(第三范式下,消除主
键之间的依赖关系)特性如下:
1. 所有非主属性对每一个码都是完全函数依赖;
2. 所有非主属性对每一个不包含它的码,也是完全函数依赖
3. 没有任务属性完全函数依赖于非码的任何一组属性
第四范式(4NF):
限制关系模式的属性间不允许有非平凡且非函数依赖的多值依赖
三、数据库设计
数据需求分析阶段:
数据需求分析是用户和设计人员对数据库应用系统所设计的内容和功能的整理和描述,
是以用户的角度来认识系统。任务是综合各个用户的应用需求,对现实世界要处理的对象进
行详细调查,了解先行系统的概况,确定新系统功能的过程中,收集支持系统目标的基础数
据和处理方法。
需求分析的重点是调查组织结构情况、调查各部门的业务活动情况、协助用户明确对新
系统的各种要求、确定新系统的边界,以此获得如下要求:
1. 信息要求:用户需要在系统中保存哪些信息,以及信息的完整性要求
2. 处理要求:用户在系统中要实现什么样的操作,对保存的信息的处理过程和方式
3. 系统要求:安全性、使用方式和可扩充性要求。
需求分析阶段的产物:数据流图、数据字典、需求说明书
概念结构设计阶段:
概念结构设计的目的是产生反映系统信息需求的数据库概念结构,集概念模式。概念
结构是独立于支持数据库的DBMS和使用的硬件环境。
概念结构设计的产物:E-R图

ER图的合并方式:1. 多个局部ER图一次集成;2. 逐步集成(每次集成2个)
集成产生的冲突和解决方法:
1. 属性冲突:同一属性在不同ER图中,属性的类型、取值范围、单位等不一致
2. 命名冲突:同名异意和异名同义
3. 结构冲突:同一实体在不同的ER图中的属性不同
ER图的优化:
1. 实体类型的合并(一对一和一对多的情况);
2. 冗余属性的消除;
3. 冗余关系的消除
逻辑结构设计阶段:
逻辑结构设计在概念结构的基础上进行,可以是层次模型、网状模型和关系模型。主要
工作包括:确定数据模型、将ER图转化为数据模型、确定完整性约束和确定用户视图。

Armstrong公理:
自反律:若属性集Y 包含于属性集X,属性集X 包含于U,则X→Y 在R 上成立
增广律:若X→Y 在R 上成立,且属性集Z 包含于属性集U,则XZ→YZ 在R 上成
立。
传递律:若X→Y 和 Y→Z在R 上成立,则X →Z 在R 上成立。
Armstrong推广规则:
合并规则:若X→Y,X→Z同时在R上成立,则X→YZ在R上也成立。
分解规则:若X→W在R上成立,且属性集Z包含于W,则X→Z在R上也成立。
伪传递规则:若X→Y在R上成立,且WY→Z,则XW→Z。
物理结构设计阶段
物理结构设计的抓哦工作步骤包括:
确定数据分布:根据不同应用分布数据;根据处理要求确定数据的分布;对数据的
分布存储必然会导致数据的逻辑结构的变化。
存储结构:数据文件中记录之间的物理结构(索引)
访问结构:数据的访问方式是有其存储结构决定的
数据库实施阶段
建立实际的数据库结构;数据加载;数据库试运行和评价
数据库维护阶段
对数据库性能的检测和改善
数据库的备份以及故障恢复
数据库重组和重构
四、数据访问层
对象关系映射(ORM)是通过使用描述对象和数据库之间映射的元数据,将程序中的对象与关系数据库相互映射,ORM可以解决数据库与程序间的异构。
映射关系表:
| 面向对象 | 关系数据库 |
| 类Class | 数据表table |
| 对象Object | 记录record |
| 属性attribute | 字段field |
常见的ORM框架:
1. Hibernate:全自动框架,强大、复杂、笨重、学习成本高
2. Mybatis:半自动框架
3. JPA(Java Persistence API):通过JDK5.0或XML描述对象-关系表的映射关系,是
Java自带的框架,Hibernate是JPA的一种实现
JPA通过JPQL描述对象与关系表之间的映射关系,由entity manager将JPSQL翻译成响
应的数据库查询语句
Hibernate与Mybatis对比:
| 纬度 | Hibernate | Mybatis |
| 简单对比 | 强大、复杂、间接、SQL无关 | 小巧、简单、直接、SQL相关 |
| 可移植性 | 好(不关心数据数据库) | 差(SQL与数据库相关) |
| 复杂多表关联 | 不支持 | 支持 |
五、数据库备份
冷备份:数据库停止的状态下,将数据库的文件全部备份
热备份:数据库运行的状态下,将数据库的数据文件备份
全量备份:备份所有数据
差量备份:近备份上次全量备份之后变化的数据
增量备份:备份上次备份之后变化的数据
六、NoSQL数据库
NoSQl(Not only SQL):非关系型数据库
| 纬度 | 关系型数据库 | 非关系型数据库 |
| 应用领域 | 面向通用领域 | 特定应用领域 |
| 数据容量 | 有限数据 | 海量数据 |
| 数据类型 | 结构化数据 | 非结构化数据 |
| 并发支持 | 支持并发、但性能低 | 支持高并发 |
| 事务 | 高事务支持 | 弱事务支持 |
| 扩展方式 | 向上扩展,硬件升级 | 向外口站,集群 |
常见的NoSQL类型:
1. 键值类型:Redis,Tokyo Cabinet/Tyrant,Voldemort, Oracle BDB
2. 列存储:HBase,Cassandra,Riak
3. 文档型: CouchDB,MongDb
4. 图形:Neo4J,InfoGrid,Infinite Graph
七、分布式关系数据库
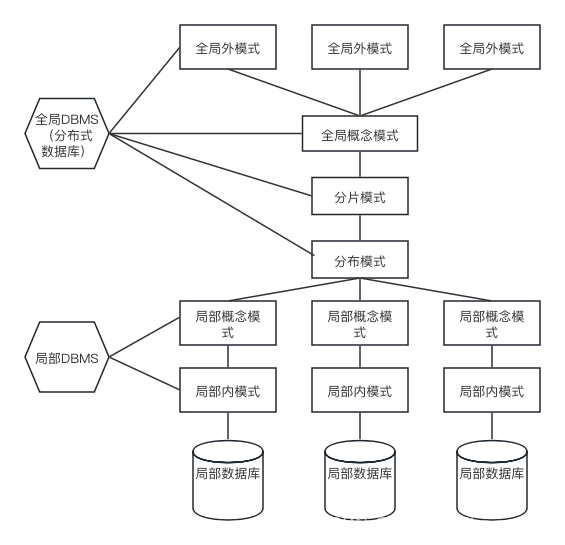
分区:将统一数据表分成多个数据文件
分表:将统一表的内容分成多个数据表
分库:将一个数据库分解成多个数据库
分区和分表的差异:
共性:1. 都针对数据表;2, 都使用了分布式存储;3.都提升了查询效率;4. 都降低了
数据库的频繁I/O压力
差异:分区逻辑上还是一张表,分表逻辑上是多张表
| 分区策略 | 分区方式 |
| 范围分区 | 按数据范围值来做分区 |
| 散列分区 | 通过对key进行hash运算分区 |
| 列表分区 | 按某字段的值进行分区 |
分区的优点:
1. 相对于单个文件系统或硬盘,分区可以存储更多的数据
2. 分区可以更方便的管理数据,比如按日期删除数据
3. 精确定位分区查询数据,不需要全表扫描,提高效率
4. 可扩多个分区查询,提高查询的吞吐量
5. 在涉及聚合函数查询时,可以很容易进行数据的合并
数据的分布透明性:
分片透明:用户感知不到如何分片(水平分、垂直分、混合分)
位置透明性:用户感知不到数据存放在哪里
复制透明性:不关心节点的复制情况
局部数据模型透明:用户或应用程序无需知道局部使用的是哪种数据模型
八、数据库的读写分离
主从数据库的结构特点:
1. 一般是一主多从,也可以多主多从
2. 主库进行写操作,从库进行读操作
主从复制步骤:
1. 主库更新数据完成前,将操作写入binlog日志文件
2. 从库打开I/O线程与主库连接,做binlog dup process操作,并将事件写入中继日志
3. 从库执行中继日志事件,保持与主库一致。