北京网站建设技术如何开发一个软件平台
目录
1 BeautifulSoup 官方文档
报错暂时保存
2 用bs 和 requests 打开 本地html的区别:代码里的一段html内容
2.1 代码和运行结果
2.2 用beautiful 打开 本地 html 文件
2.2.1 本地html文件
2.2.2 soup1=BeautifulSoup(html1,"lxml")
2.3 用requests打开 本地 html 文件
2.3.1 本地html文件
2.3.2 print(html1)
3 用bs 和 requests 打开 本地html的区别:一个独立的html文件
3.1 独立创建一个html文件
3.2 下面是新得代码和运行结果
3.3 用beautiful 打开 本地 html 文件
3.4 用 read() 打开 本地 html 文件
3.5 用requests打开 本地 html 文件
4 f.write(soup1.prettify()) 和 html 用 read()读出来 差别很大
1 BeautifulSoup 官方文档
Beautiful Soup: We called him Tortoise because he taught us.![]() https://www.crummy.com/software/BeautifulSoup/
https://www.crummy.com/software/BeautifulSoup/

Beautiful Soup 4.4.0 文档 — Beautiful Soup 4.2.0 中文 文档![]() https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Beautiful Soup 4.4.0 文档 — beautifulsoup 4.4.0q 文档![]() https://beautifulsoup.readthedocs.io/zh_CN/latest/
https://beautifulsoup.readthedocs.io/zh_CN/latest/

报错暂时保存
r""
OSError: [Errno 22] Invalid argument: 'E:\\work\\FangCloudV2\\personal_space\x02learn\\python3\\html0003.html'

soup1=BeautifulSoup(open(html1,"html.parser"))
ValueError: invalid mode: 'html.parser'

with open(path1 ,"a") as f
^
SyntaxError: expected ':'

- soup1=BeautifulSoup(html1,"lxml")
- lxml 是解析方式
- 如果不写,默认也会采用 lxml的解析
- 如果写成 soup1=BeautifulSoup(html1) 可以正常运行,但是会提醒
AttributeError: 'str' object has no attribute 'text'

requests.exceptions.InvalidSchema: No connection adapters were found for '<html><head><title>The Dormouse\'s story</title></head>\n<body>\n<p class="title"><b>The Dormouse\'s story</b></p>\n\n<p class="story">Once upon a time there were three little sisters; and their names were\n<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,\n<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and\n<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;\nand they lived at the bottom of a well.</p>\n\n<p class="story">...</p>\n'

2 用bs 和 requests 打开 本地html的区别:代码里的一段html内容
2.1 代码和运行结果
#E:\work\FangCloudV2\personal_space\2learn\python3\py0003.txtimport requests
from bs4 import BeautifulSoup#html文件内容
html1 = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""#"测试bs4"
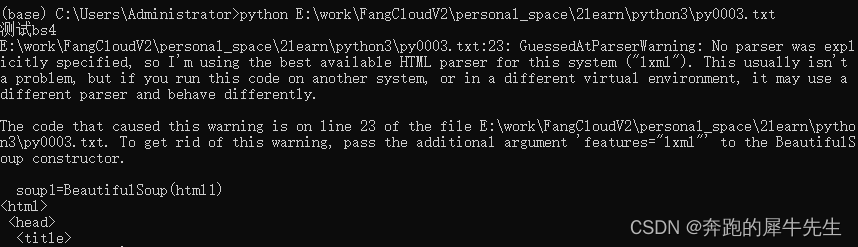
print ("测试bs4")
soup1=BeautifulSoup(html1,"lxml")
print (soup1.prettify())#"对比测试requests"
print ("对比测试requests")
#res=requests.get(html1)
res=html1
#print (res.text)
print (res)

2.2 用beautiful 打开 本地 html 文件
#"测试bs4"
html1=""" ... """
print ("测试bs4")
soup1=BeautifulSoup(html1,"lxml")
print (soup1.prettify())
2.2.1 本地html文件
- 这次的本地html 文件是写在 python 脚本内容一起的 一段文本
- html1=""" ... """
2.2.2 soup1=BeautifulSoup(html1,"lxml")
- 正确写法
- soup1=BeautifulSoup(html1,"lxml")
- lxml 是解析方式
- 如果不写,默认也会采用 lxml的解析
- 如果写成 soup1=BeautifulSoup(html1) 可以正常运行,但是会提醒
2.3 用requests打开 本地 html 文件
#"对比测试requests"
print ("对比测试requests")
#res=requests.get(html1)
res=html1
#print (res.text)
print (res)
2.3.1 本地html文件
- 这次的本地html 文件是写在 python 脚本内容一起的 一段文本
- html1=""" ... """
- 本地文件 html 已经是一段 脚本内的文本 """ ..."""
2.3.2 print(html1)
本地文件 html 已经是一段 脚本内的文本 """ ..."""
- 正确写法1
- res=html1
- print (res)
- 正确写法2
- print (html1)
- 错误写法1
- #print (res.text)
- 只有html作为网页结构的时候,可以用 html.text 取到其中的string 内容
- 所以
- requests.get(url)
- requests.get(url).text
requests.exceptions.InvalidSchema: No connection adapters were found for '<html><head><title>The Dormouse\'s story</title></head>\n<body>\n<p class="title"><b>The Dormouse\'s story</b></p>\n\n<p class="story">Once upon a time there were three little sisters; and their names were\n<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,\n<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and\n<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;\nand they lived at the bottom of a well.</p>\n\n<p class="story">...</p>\n'
- 错误写法2
- #res=requests.get(html1)
- 一样的原因
- 因为这里的html1 不是网页,而已经是网页的内容string了!
AttributeError: 'str' object has no attribute 'text'
3 用bs 和 requests 打开 本地html的区别:一个独立的html文件
3.1 独立创建一个html文件


3.2 下面是新得代码和运行结果
代码
#E:\work\FangCloudV2\personal_space\2learn\python3\py0003-1.txt
#E:\work\FangCloudV2\personal_space\2learn\python3\html0003.htmlimport requests
import os
import time
from bs4 import BeautifulSouppath1=r"E:\work\FangCloudV2\personal_space\2learn\python3\html0003.html"
soup1=BeautifulSoup(open(path1))
print ("测试bs4")
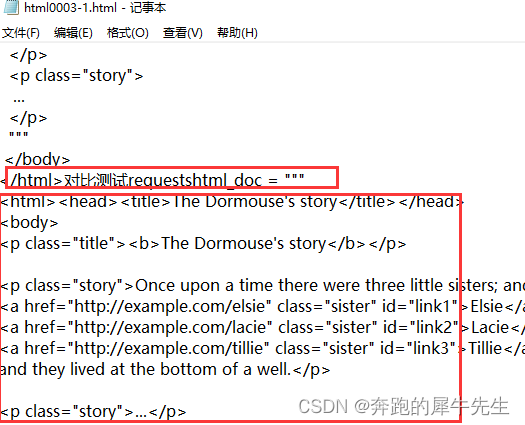
print (soup1.prettify())path2=r'E:\work\FangCloudV2\personal_space\2learn\python3\html0003-1.html'
if not os.path.exists(path2): os.mkdir(path2) with open(path2 ,"a") as f:f.write("测试bs4")f.write(soup1.prettify())print ("对比测试requests")
with open(path1 ,"r") as f:res=f.read()
print (res)with open(path2 ,"a") as f:f.write("对比测试requests")f.write(res)"""
#地址,路径,前都记得加 r, 因为string 内部包含\/等转义符,rawdata安全
url1="E:\work\FangCloudV2\personal_space\2learn\python3\html0003.html"
url1=r"E:\work\FangCloudV2\personal_space\2learn\python3\html0003.html"
res=requests.get(url1)
#本地地址不能像网址 url这样用,用的\/不同,即使用 raw r 也不行. 可以用转格式函数吗?
#https://www.baidu.com/
"""
运行结果


另存为的文件内容

3.3 用beautiful 打开 本地 html 文件
path1=r"E:\work\FangCloudV2\personal_space\2learn\python3\html0003.html"
soup1=BeautifulSoup(open(path1))
print ("测试bs4")
print (soup1.prettify())path2=r'E:\work\FangCloudV2\personal_space\2learn\python3\html0003-1.html'
if not os.path.exists(path2):
os.mkdir(path2)with open(path2 ,"a") as f:
f.write("测试bs4")
f.write(soup1.prettify())
最大的差别
- soup1=BeautifulSoup(open(path1))
- soup1.prettify() 输出格式化得内容

3.4 用 read() 打开 本地 html 文件
- 和 read()读出来的内容 (应该和 requests.get()得出来得内容一样)
print ("对比测试requests")
with open(path1 ,"r") as f:
res=f.read()
print (res)with open(path2 ,"a") as f:
f.write("对比测试requests")
f.write(res)
3.5 用requests打开 本地 html 文件
- 没试过
- 这种本体html没法试把?
4 f.write(soup1.prettify()) 和 html 用 read()读出来 差别很大
和 read()读出来的内容 (应该和 requests.get()得出来得内容一样)