建筑公司企业愿景与使命seo怎么推排名
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
lxml使用流程
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,下面简单介绍一下 lxml 库的使用流程:
(1)导入模块
from lxml import etree
(2)创建解析对象
调用etree模块的HTML() 方法来创建HTML解析对象:
parse_html = etree.HTML(html)
HTML()方法能够将HTML标签字符串解析为HTML文件,该方法可以自动修正HTML 文本。
(3)调用xpath表达式
最后使用第二步创建的解析对象调用xpath()方法,完成数据的提取。
r_list = parse_html.xpath('xpath表达式')
xpath常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
下面结合lxml使用流程和xpath常用规则举几个例子,假定我们要处理的HTML代码如下:
<div class="wrapper"><a href="www.biancheng.net/product/" id="site">website product</a><ul id="sitename"><li><a href="http://www.biancheng.net/" title="编程帮">编程</a></li><li><a href="http://world.sina.com/" title="新浪娱乐">微博</a></li><li><a href="http://www.baidu.com" title="百度">百度贴吧</a></li><li><a href="http://www.taobao.com" title="淘宝">天猫淘宝</a></li><li><a href="http://www.jd.com/" title="京东">京东购物</a></li><li><a href="http://c.bianchneg.net/" title="C语言中文网">编程</a></li><li><a href="http://www.360.com" title="360科技">安全卫士</a></li><li><a href="http://www.bytesjump.com/" title=字节">视频娱乐</a></li><li><a href="http://bzhan.com/" title="b站">年轻娱乐</a></li><li><a href="http://hao123.com/" title="浏览器">搜索引擎</a></li></ul>
</div>
(1)提取所有a标签内的文本信息
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//a/text()'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
(2)获取所有href的属性值
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//a/@href'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
(3)获取ul标签下的li标签下的a标签的href属性值
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//ul[@id="sitename"]/li/a/@href'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
案例——爬取某一地区所有企业名称
这里有一个网站:http://m.54114.cn/luoyang/。以洛阳为例,里面按行业列出了该地区所有企业的名称。
通过进入不同的行业内查看,我们能发现他的url是有规律的:
http://m.54114.cn/luoyang/hangye1/、http://m.54114.cn/luoyang/hangye2/、……、一直到huangye20。
在翻看不同页的内容时,我们也发现url是有规律的:比如第二页的url是http://m.54114.cn/luoyang/hangye1_p2/,第三页的最后就是p3,依次类推。虽然第一页没有“_p1”的后缀,但是我们按照此规律进行尝试,发现也可以访问,这就简单了。
点进某一行业的页面,有几个东西是我们感兴趣的。首先就是这个标题。
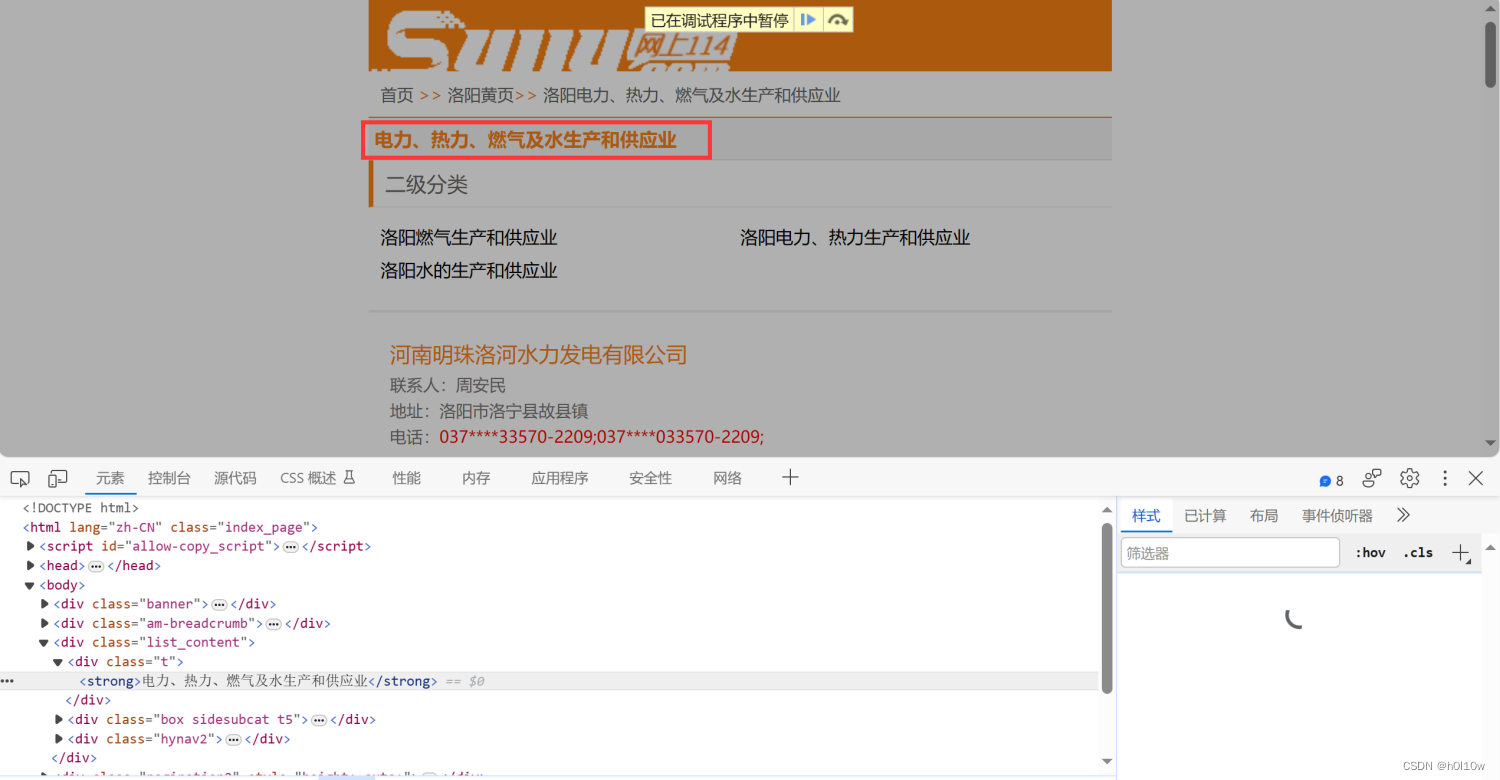
通过html文档结构,我们能得到其对应的xpath为://div[@class="list_content"]/div[1]/strong/text()
然后就是这个总页数
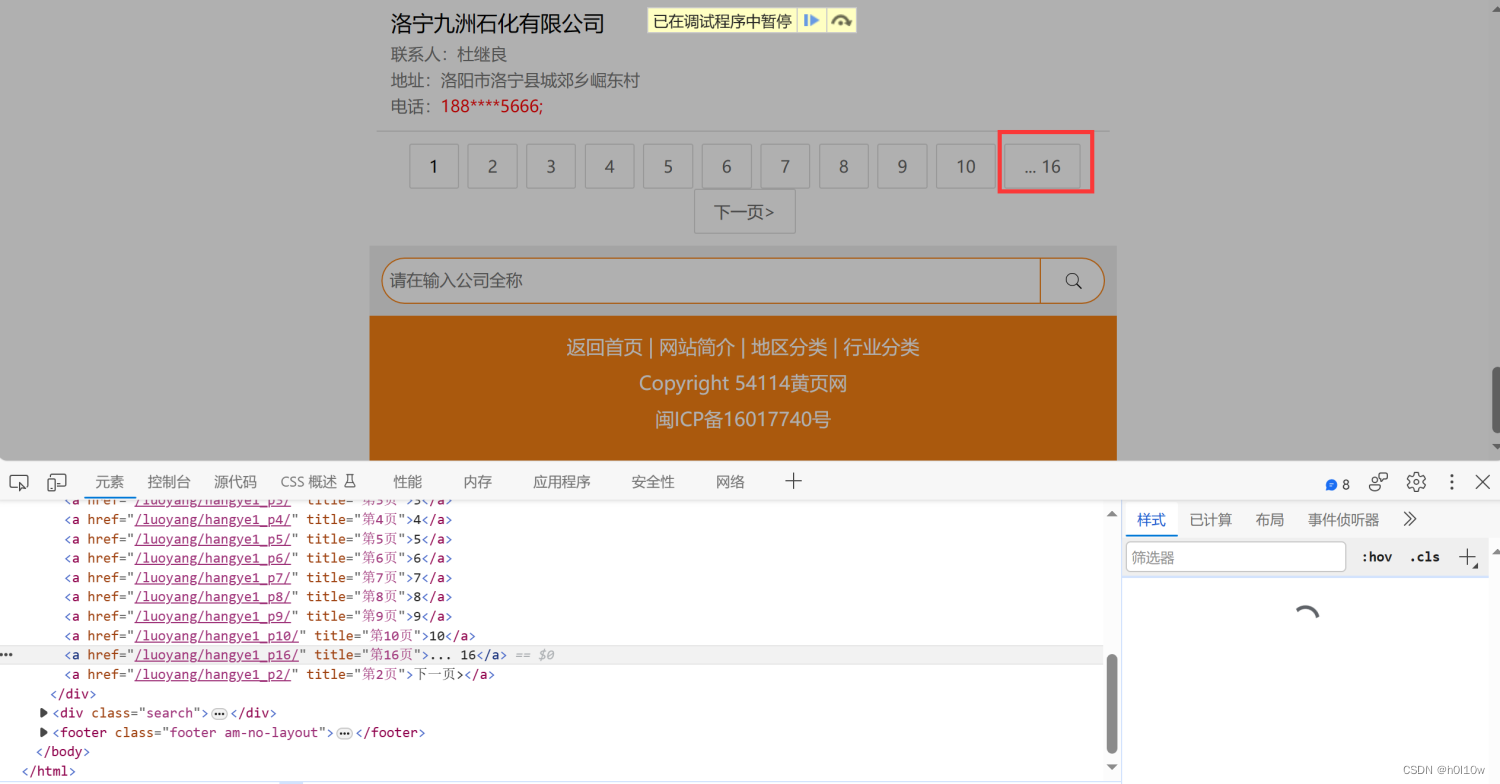
总页数是倒数第二个a标签,所以我们能得到其对应的xpath为://div[@class="pagination2"]/a[last()-1]/@title。
最后就是我们关心的企业名称
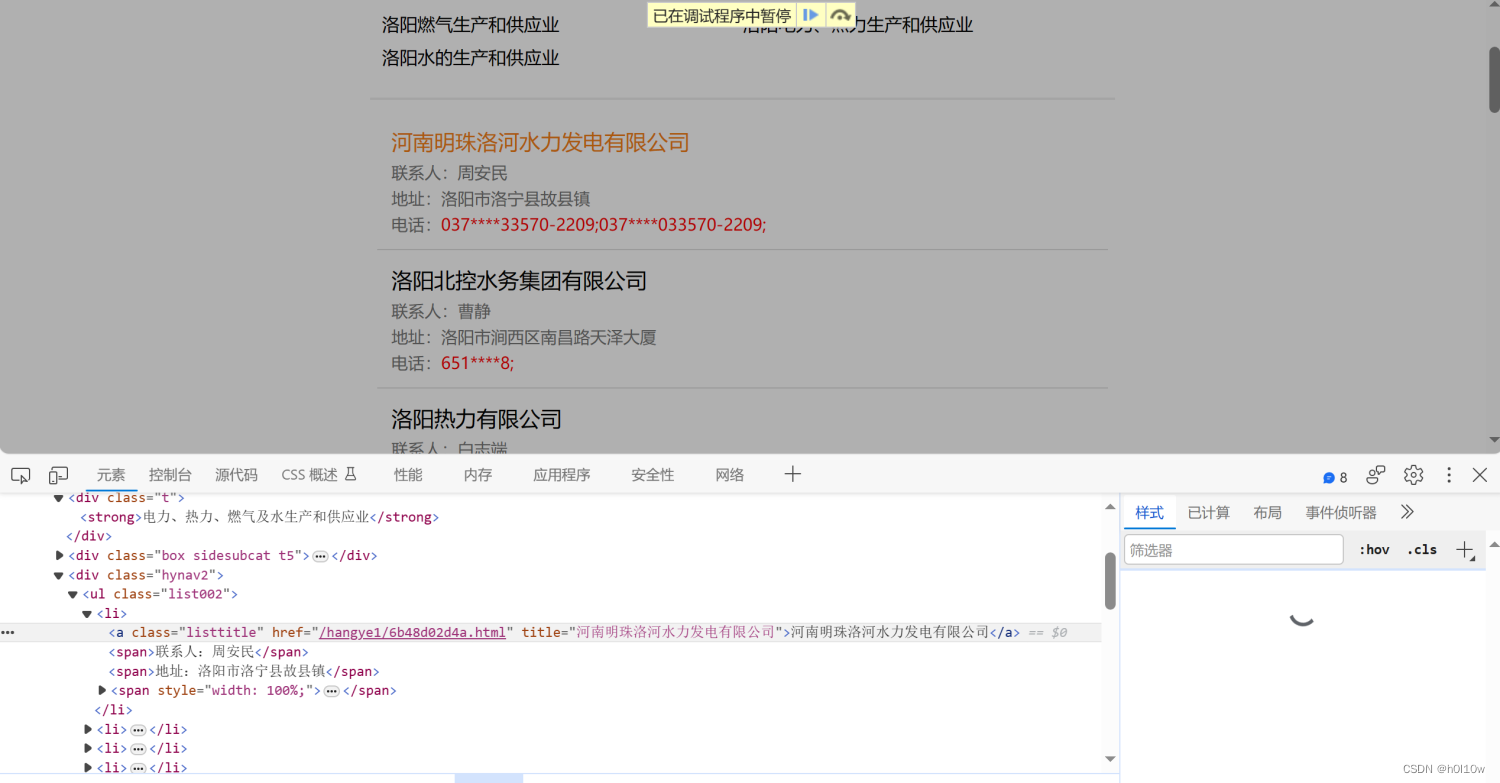
xpath为://div[@class="list_content"]/div[3]/ul/li/a/text()
最后得到总的爬取脚本:
import requests
from lxml import etree# url = 'http://m.54114.cn/luoyang/hangye12_p1/'
headers = {'User-ASgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0','Host': 'm.54114.cn','Cookie': 'ZDEDebuggerPresent=php,phtml,php3'
}def get_content(url, xpath):response = requests.get(url, headers=headers)tree = etree.HTML(response.text)target = tree.xpath(xpath)return targetfor i in range(1, 21):url = f'http://m.54114.cn/luoyang/hangye{i}_p1/'response = requests.get(url, headers=headers)tree = etree.HTML(response.text)filename = tree.xpath('//div[@class="list_content"]/div[1]/strong/text()')[0]pages = tree.xpath('//div[@class="pagination2"]/a[last()-1]/@title')if len(pages) == 0:continuepages = int(pages[0][1:-1])file = open('./luoyang/' + filename + '.txt', 'w')for j in range(1, pages + 1):url = f'http://m.54114.cn/luoyang/hangye{i}_p{j}/'xpath = '//div[@class="list_content"]/div[3]/ul/li/a/text()'names = get_content(url, xpath)for name in names:file.write(name + '\n')file.close()执行完的效果如下
