外国人在中国做视频网站sem运营
参考资料:活用pandas库
1、简单线性回归
线性回归的目标是描述响应变量(或“因变量”)和预测变量(也称“特征”、“协变量”、“自变量”)之间的直线关系。本例中将讨论tips数据集中的total_bill对tip的影响。
# 导入pandas库
import pandas as pd
# 导入数据集
tips=pd.read_csv(r"...\seaborn常用数据案例\tips.csv")
# 展示数据集
print(tips.head())
(1)使用统计模型库
具体相关资料可参考:python统计分析——线性模型的预测和评估_python 线性拟合评估-CSDN博客
# 导入statsmodels库的formula API
import statsmodels.formula.api as smf
# 用普通最小二乘法进行公式拟合
model=smf.ols("tip~total_bill",data=tips)
results=model.fit()
# 用params属性查看线性方程的系数
print(results.params)
# 用conf_int()方法查看置信区间
print(results.conf_int())
# 用summary方法查看整体的结果
print(results.summary())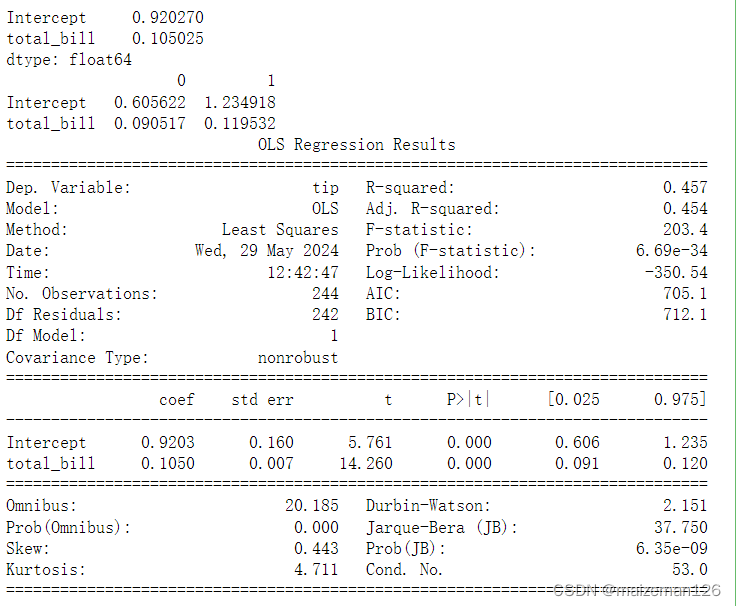
(2)使用sklearn库
由于sklearn接收的是numpy数组,所以有时需要处理数据,以便把DataFrame传入sklearn。如果输入的不是矩阵数据,则需要重塑输入。根据是否只有一个变量或者一个样本,要分别指定reshape(-1,1)或reshape(1,-1)。
# 从sklearn库中导入linear_model模块
from sklearn import linear_model
# 创建LinearRegression()对象
lm=linear_model.LinearRegression()
# 对数据进行拟合
# 注意参数中X是大写,输入的参数是矩阵而非向量
# y是小写,输入的参数是向量
predicted=lm.fit(X=tips['total_bill'].values.reshape(-1,1),y=tips['tip'])
# 输出线性方程的系数
print(predicted.coef_)
# 输出线性方程的截距
print(predicted.intercept_)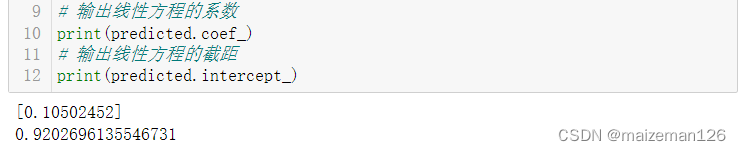
2、多元回归
多元线性回归的系数,是在所有其他变量保持不变的情况下进行解释的。
(1)使用statsmodels库
用多元回归模型拟合数据集与拟合简单的线性回归模型非常相似。在formula参数中,可以轻松地把其他协变量“添加”到波浪线的右边。
# 使用statsmodels库进行多元线性回归的拟合
model=smf.ols("tip~total_bill + size",data=tips).fit()
# 输出结果
print(model.summary())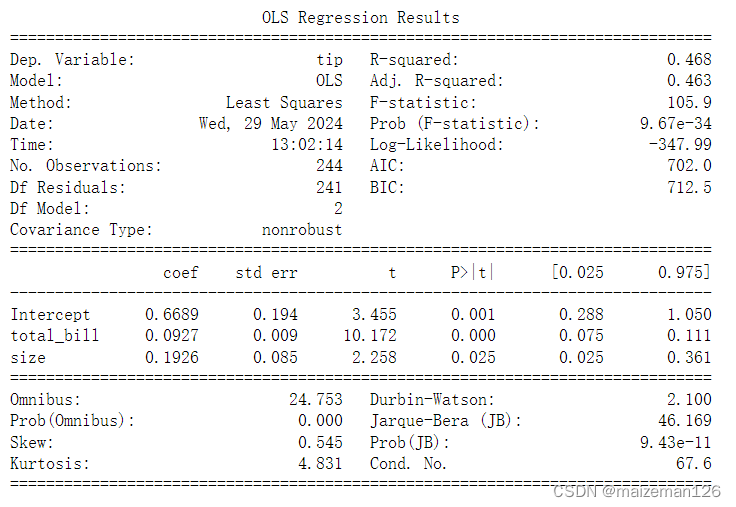
(2)使用statsmodels和分类变量
对分类变量建模时,必须创建虚拟变量,即分类中的每个唯一值都变成了新的二元特征。statsmodels会自动创建虚拟变量。为了避免多重共线性,通常会删除其中一个虚拟变量。
# 拟合所有的变量
model=smf.ols("tip~total_bill + size + sex + smoker + day + time",data=tips).fit()
# 输出结果
print(model.summary())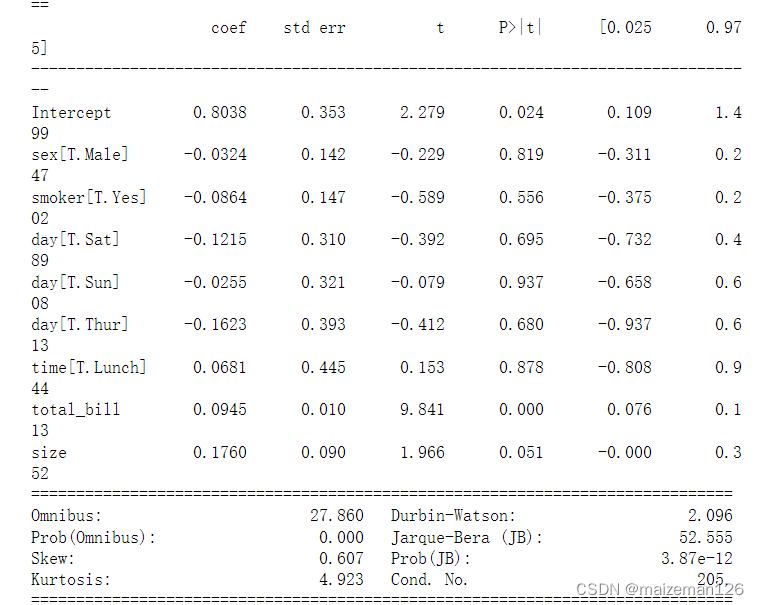
对于分类变量的解释必须和参考变量(即从分析中删除的虚拟变量)联系起来。例如sex[T。Female]的系数为0.0324,解释该值时要与参考值(Male)联系起来。也就是说,当sex从Male变为Female时,tip增加0.0324。
(3)使用sklearn库
在sklearn中,多元回归语法与库中的简单线性回归语法相似,为了想模型添加更多特征,可以把要使用的列传入模型。
# 创建LinearRegression对象
lm=linear_model.LinearRegression()
# 多元线性回归拟合
predicted=lm.fit(X=tips[['total_bill','size']],y=tips['tip'])
# 输出系数和截距
print(predicted.coef_)
print(predicted.intercept_)
(4)使用sklearn和分类变量
必须手动为sklearn创建虚拟变量,可以使用pandas的get_dummies函数来实现。该函数会自动把所有分类变量转换为虚拟变量,所以不必再逐个传入各列。sklearn中OneHotEncoder函数与之类似。
# 用get_dummies函数创建虚拟变量
tips_dummy=pd.get_dummies(tips[['total_bill','size','sex','smoker','day','time']])
# 展示tips_dummy
print(tips_dummy.head())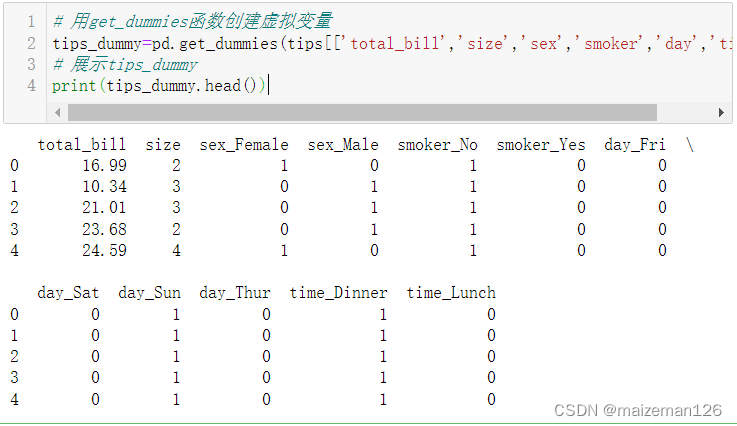
可以向get_dummies函数传入drop_first=True来删除参考变量。
x_tips_dummy_ref=pd.get_dummies(tips[['total_bill','size','sex','smoker','day','time']],drop_first=True)
print(x_tips_dummy_ref.head())
lm=linear_model.LinearRegression()
predicted=lm.fit(X=x_tips_dummy_ref,y=tips['tip'])
print(predicted.coef_)
print(predicted.intercept_)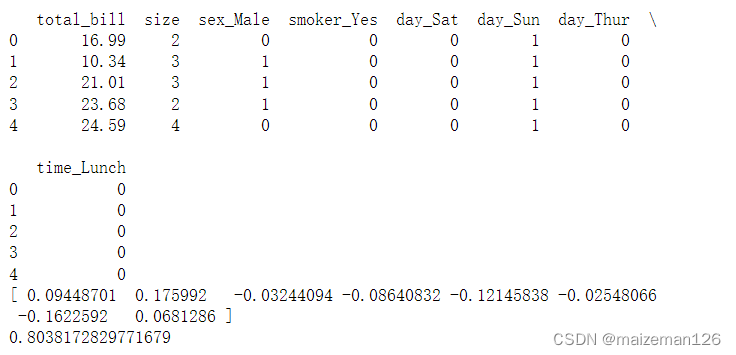
3、保留sklearn的索引标签
在尝试解释sklearn模型时,一个棘手的问题就是模型的系数不带标签,原因是numpy ndarray无法存储这类元数据。如果想让输出结果和statsmodels类似,需要手动存储标签,并添加系数。
# 导入numpy库
import numpy as np
# 创建模型并拟合
lm=linear_model.LinearRegression()
predicted=lm.fit(X=x_tips_dummy_ref,y=tips['tip'])
# 获取截距以及其他系数
values=np.append(predicted.intercept_,predicted.coef_)
# 获取值得名称
names=np.append('intercept',x_tips_dummy_ref.columns)
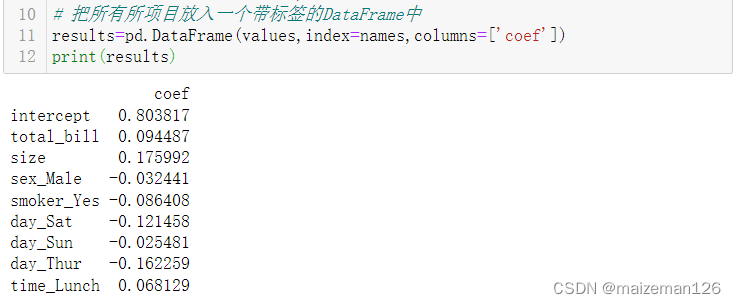
# 把所有所项目放入一个带标签的DataFrame中
results=pd.DataFrame(values,index=names,columns=['coef'])
print(results)